Introduction
CQRS, which stands for Command Query Responsibility Segregation, is a new approach in DDD which optimizes a system for writing and reading data respectively by separating these two processes from one another. Modern CQRS-architectures allow for highly scalable systems on both the read- and the write-part of the system. Implementing a CQRS-architecture also has downsides as it is highly likely to increase cost and complexity of the system. So it’s always a thin line to decide whether CQRS can help in the current system or whether it will overcomplicate things with no real benefit.
Commands and Queries
The basis of CQRS are commands and queries. Commands are the write-part of the system. In very general terms, commands do something in the system and should modify the current state of the system. Commands also should not return a value for whatever action they have done. In a classic Todo-application, a command could be “Set Todo item to done” or “Create a new Todo item with title X”.
On the other hand, queries are the read-part of the system. They should not modify the state of the system, but answer a question (in the domain-space) and thus also return some sort of value. In the todo-example, such a query could be “Is item X done?” or “How many items are open?”.
As you can see, both constructs are heavily influenced by the “domain-thinking”. There is no mention of databases, SQL or persistence. In the end these commands and queries will interact with some sort of persistence-layer, but for CQRS-design this doesn’t really matter as it is all about the domain and how to interact with it.
You can also have exceptions to those rules above regarding what a command and what a query should and should not do. If you, for example, want to create a new todo-item using a command, it is highly likely (and probably also makes sense) that the command returns some sort of identifier for the newly created item, so that the application can later work with that item. In these cases it can make sense to brake the basic rules of commands and queries, because if you would follow the rules all the time it could cause a lot of added and unecessary complexity.
So the pratical rule is to follow the segregation of commands and queries where possible, but not to overcomplicate a system just to follow the rules.
CQRS Architectures
CQRS can be followed in the architecture of the software quite easily. To achive the responsibility segregation, you can split your application layer into two stacks: The command stack and the query stack. A presentation-layer sitting on top of the application-layer can then interact with both the query- and the command-stack in the application layer. This way, you have one side of the application-layer (queries) that you can optimize for read and one (commands) that you can optimize for writes.
To optimize for reading, you could de-normalize your read-database to achieve faster query-times by avoiding joins and aggregations. To optimize write-operations, a NoSQL-database could be used. CQRS allows you to tweak each side of the system to perform its main functionality as good and fast as possible.
To visualize this a little easier, here are 3 types of architectures where CQRS is applied.
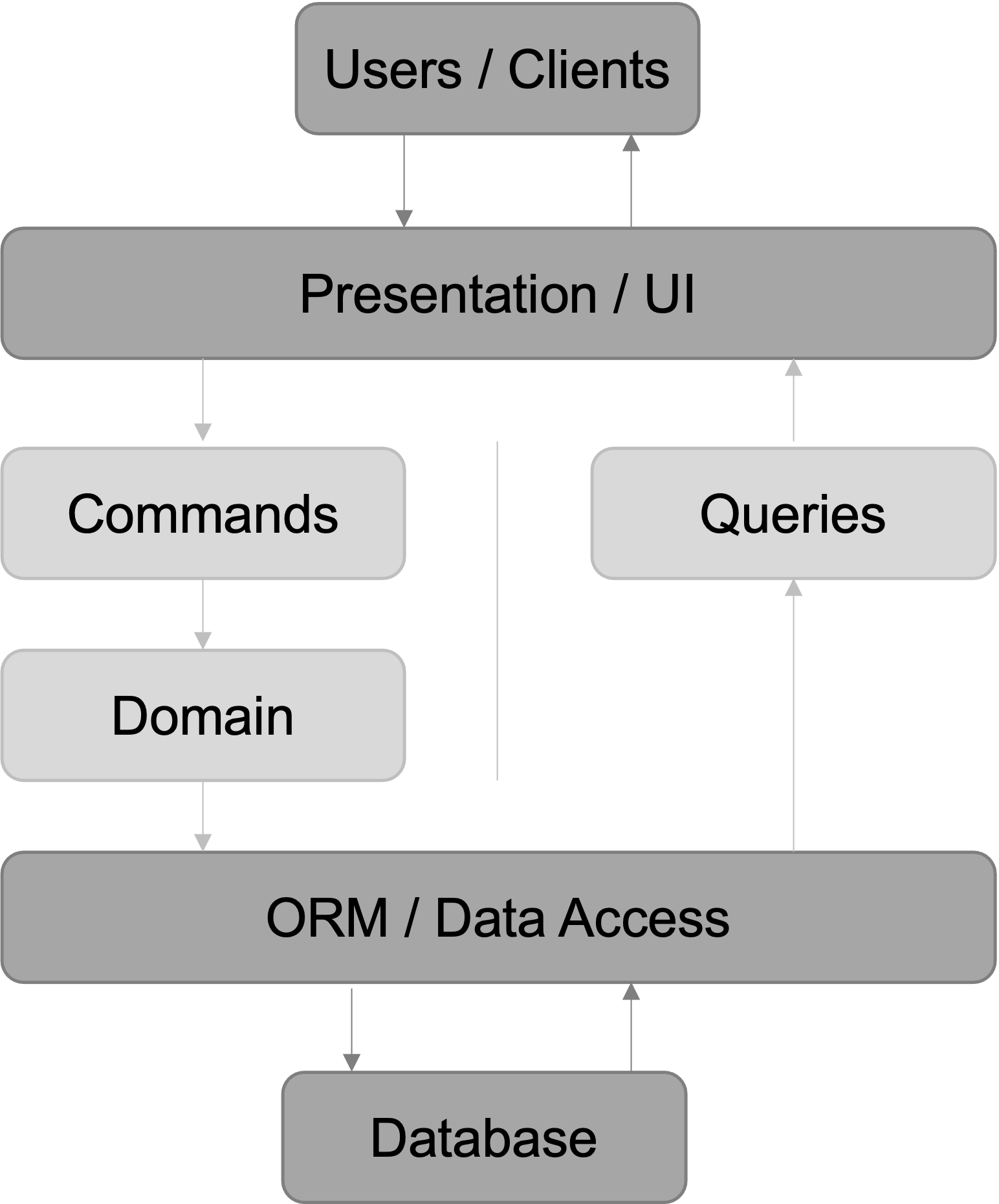
Single database
This one is the easiest and most straight-forward implementation. The presentation- and database-layers aren’t changed at all. The application-layer is split into the two stacks mentioned before and optimizations are done in the application-layer directly. This setup is achieved rather quickly and easily because only the application-layer has to be touched.
This setup is also a good starting point if you want to move your application to a CQRS-setup. As soon as this setup is achieved, other more advanced setups can be introduced to build on top of the current one. The commands will use the domain-dependency to change the state of the system while queries use the database through some sort of data access layer to get data from the persistence-layer.
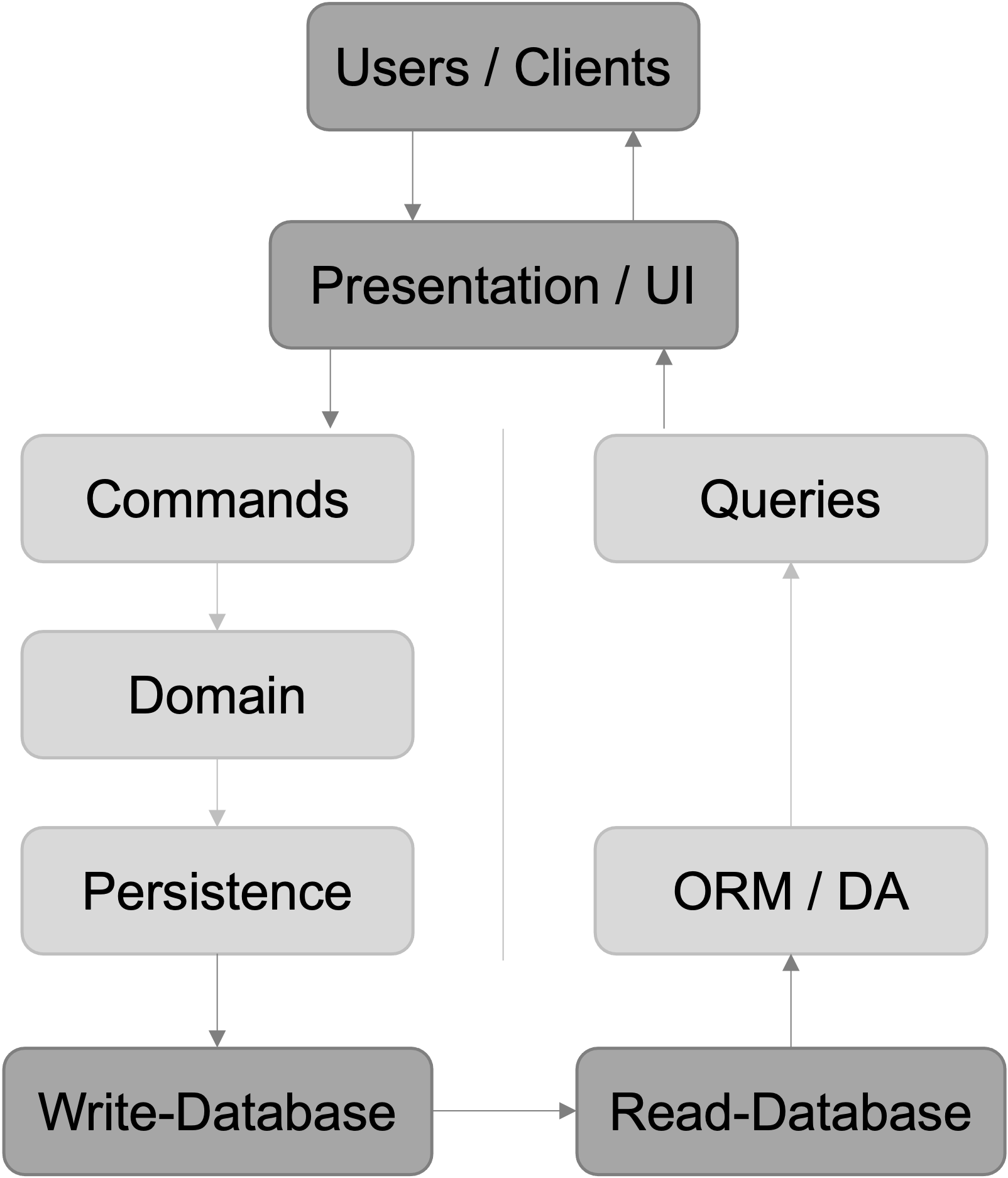
Two databases
This architecture is an evolved version of the first one. It is pretty similar but uses eventual consistency and two seperate databases to optimize for read and write operations respectively. With this setup you can use completly different technologies on the persistence-layer to give you the best performance on both sides of the system. It is a lot faster than the first architecture, but comes with added cost and complexity due to more than one database.
The commands still only interact with the domain-model to modify the state of the system. The domain-model then communicates with a persistence-layer which stores the data in a write-optimized datastore. This could be a relational database in third normal form or a NoSQL-store. On the other side, all queries will go through some sort of ORM or data access layer and get data from the read-optimized datastore. This could be a denormalized relational database which gives you quicker response times due to the fact that no joins would be needed.
Between the two databases is some sort of synchronization-process which will keep both databases in sync. But it’s important to remember that the system is only eventually consistent because it takes time to move the data from the write- to the read-database. Usually this is done in milliseconds, but the application- and especially the data-layers have to be designed in a way to take this eventual consistency into account.
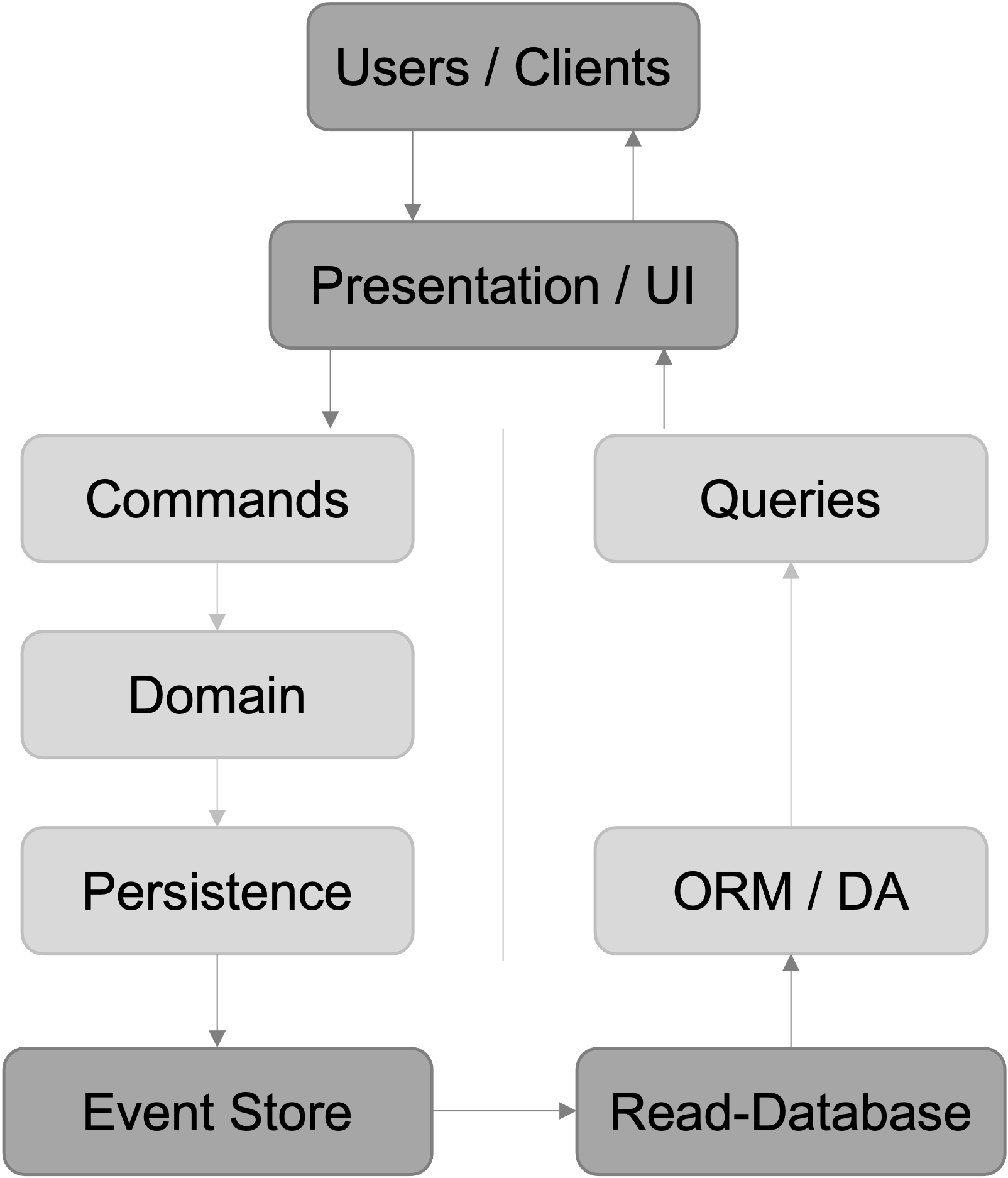
Event sourcing
The last and most complex architecture is called Event Sourcing. It is pretty similar to the second setup, but uses a so called “Event Store” instead of a write-optimized database on the command side. The big difference to the second architecture is that we store all changes that are made to an entity in the event store instead of just the latest state of an entity. You can compare it to a history of events that “happend” to an entity. The synchronization process that keeps the read-database up-to-date can apply all events that happend to an entity chronologically to end up with the latest and most up-to-date state of this specific entity.
This setup is more complex than the two database architecture from before, but it also has a few advantages if used in the correct cases. Due to the nature of the event store, you have a complete and correct audit trail of all modifications that happend to an entity over time. In more heavily regulated industries like banking, this could be an advantage and could save money and ressources because you don’t need an additional system to keep track of that. It also allows you to go back to any state an entity has ever been in, which can be useful for testing and for debugging issues.
The downside to event sourcing is that it adds cost and complexity to the system. So before using it, be sure that you can take advantage of the benefits event sourcing offers.